איך עובד GPT?
ChatGPT של OpenAI ממשיך להדהים את האינטרנט. החלטתי לחקור בעצמי כיצד בנוי המודל.
אחד הטרנדים החמים בתקופה האחרונה בתחום הלמידה העמוקה ובפרט בעיבוד שפה טבעית, הוא LLM (מודל שפה גדול - large language model). הבולט מבין ה-LLMs הוא GPT-3 של OpenAI עם 175 מיליארד פרמטרים, שהוא למעשה גרסה מוגדלת של GPT-2, אותו אחקור במאמר זה. חברות נוספות, כגון אנבידיה ומטא, הציגו LLMs עם ארכיטקטורה כמעט זהה.
מאמר עם פירוט טכני מסודר ומעמיק של LLM כזה יכול לסייע לעבודה עם LLMs דומים ולהוות רפרנס שימושי. מכיוון שלא מצאתי מאמר מקיף לגמרי, במיוחד לא בעברית, החלטתי לכתוב אחד.
תוכן עניינים
רקע טכני
לעומת GPT-3, הקוד של GPT-2 פתוח ונגיש לציבור, ולכן אחקור דווקא אותו. ההבדל העיקרי בין הדורות הוא גודל המודל.
המודל GPT-2 של OpenAI הינו causal language model. המודל הוצג לראשונה ב-2019 במאמר "Language Models are Unsupervised Multitask Learners".
Language model - התפלגות, חלוקת הסתברות, מעל רצפי מילים. בהינתן רצף מילים, הוא נותן הסתברות לקיום הרצף בשפה.
Causal language model - מודל שמקבל טקסט וצריך לחזות את המילה הבאה. ל-causal language model יש רק את המילים משמאל למילה החסרה (או רק מימין, אם מדובר בשפה שכתובה מימין לשמאל כמו עברית), וכל מילה באוצר המילים של המודל מקבלת הסתברות להתאמה בטקסט. ההבדל הוא בעיקר לעומת masked language model (כמו BERT של גוגל), שלו יש את המילים משני צידי המילה החסרה.
LLM כזה חוזה את המילה הבאה בטקסט, אבל בעזרת היכולות השפתיות שהוא רוכש, ניתן להתאים אותו לשלל של downstream tasks. משימות כגון סיכום טקסטים, תרגום, מענה על שאלות, סיווג וכד׳ (לפעמים לאחר אימון נוסף).
המודל GPT-2 הוא מודל מסוג transformer. זוהי ארכיטקטורה שהוצגה לראשונה במאמר "Attention Is All You Need" ב-2017. החידוש העיקרי של ה-transformer הוא שכבת ה-self attention. על השכבה הזו אפרט בהמשך.
GPT-2 אומן לעשות causal language modeling על מאגר של כ-8 מיליון דפי אינטרנט, במשקל כולל של כ-40 גיגהבייט. בתור causal language model, הוא למעשה מסוגל לכתוב טקסטים בעצמו. החוקרים ראו שללא אימון מיוחד נוסף, המודל מסוגל להפגין יכולות של הבנת הנקרא, סיכום טקסטים, תרגום ומענה על שאלות.
טוקניזציה
כיצד נקודד את הטקסט? המחשב הרי אינו יודע לקרוא מילים. מילים, כרצפים של אותיות, חסרות משמעות עבורו. לעומת זאת, כידוע, מחשבים אוהבים מספרים, ויודעים לעבד מספרים. לכן, נייצג את הטקסט שלנו בתור רצף טוקנים, כשלכל טוקן ערך מספרי ייחודי (שהינו למעשה אינדקס מתוך אוצר מילים שנרכיב). למערכת שמקודדת את הטקסט לטוקנים קוראים טוקנייזר (tokenizer).
ישנם טוקנייזרים אשר מייצגים כל מילה בתור טוקן נפרד, וישנם אחרים אשר מייצגים כל תו בתור טוקן נפרד. המודל GPT-2 משתמש ב-Byte Pair Encoding (או בקיצור - BPE), שמשלב בין שתי הגישות. רצפים שכיחים של תווים מיוצגים כטוקן אחד, ואילו ברצפים נדירים יותר, כל תו מיוצג כטוקן נפרד. היתרון הוא שהקידוד יעיל ביותר, וגם כל הטקסט שלנו יקודד לטוקנים, ללא טוקן <unk> שיש בשיטות קידוד אחרות לסימון מילים לא מוכרות.
(הערה: התיאור להלן הוא ספציפי למימוש BPE ב-GPT-2.)
עבור אימון הטוקנייזר (שלב נפרד מאימון המודל), גודל אוצר המילים מוגדר כהיפר פרמטר. במקרה של GPT-2, באוצר המילים ישנם 50,257 טוקנים - מתוכם 256 תווי בסיס (גודל של בית אחד), 50,000 מיזוגים (ארחיב בהמשך) וטוקן <|endoftext|> לסימון הסוף של כל קטע.
תחילה, בשלב הקדם-טוקניזציה (pretokenization), הטוקנייזר מפריד את הטקסט למילים לפי הרווחים, כאשר קטגוריות שונות של תווים (אותיות, ספרות, סימני פיסוק, וכו׳) נחשבות למילים נפרדות.
בנוסף, הוא מחשיב את הסיומות:
's, 't, 're, 've, 'm, 'll, 'd
בתור מילים נפרדות.
לטוקנייזר יש מילון שמתאים בין המספרים מ-0 עד 255 (כל הערכים האפשריים עבור בית אחד) לבין תווי Unicode, להם נקרא תווי בסיס. אופן ההתאמה בין מספר לתו חסר משמעות, אך נבחרו רק תווים ברי הדפסה שאינם רווחים לבנים. המטרה היא לייצג את כל הערכים האפשריים עבור בית אחד כתווים בר הדפסה.
עבור כל מילה שהתקבלה משלב הקדם-טוקניזציה, הטוקנייזר מתרגם את הבתים שבה לתווי בסיס על פי המילון שתואר.
בעת אימון הטוקנייזר, תחילה הוא מפצל כל מילה ל"יחידות", כשכל יחידה היא למעשה תו בסיס. למשל, "hello" תיהפך ל-('h', 'e', 'l', 'l', 'o').
את המשך התהליך הוא מבצע באופן רקורסיבי:
הוא יוצר קבוצה של כל הזוגות של יחידות עוקבות. למשל, {('h', 'e'), ('e', 'l'), ('l', 'l'), ('l', 'o')}.
לאחר מכן נבחר הזוג הכי נפוץ בטקסט, ממוזג, וכל הופעה שלו בטקסט מוחלפת ביחידה אחת ממוזגת. למשל אם ('h', 'e') הוא הזוג הכי נפוץ, אז נקבל ('he', 'l', 'l', 'o').
את המיזוג נשמור בקובץ gpt2-merges.txt, כשהיחידה הראשונה והשנייה מופרדות באמצעות רווח. למעשה, סדר המיזוגים בקובץ הוא לפי הסדר שבו מיזגנו את הטקסט באימון.
את התהליך הזה נמשיך עד שיתמלא לנו המקום למיזוגים (לפי גודל אוצר המילים שנבחר כהיפר פרמטר).
לאחר שיש לנו טוקנייזר מאומן, כשנרצה לקודד מילה, נשתמש בקובץ gpt2-merges.txt שיצרנו, ובכל איטרציה נמזג את הזוג של יחידות עוקבות במילה שנמצא הכי גבוה בקובץ.
כעת, כל יחידה היא תו בסיס או מיזוג. נתייחס לכל יחידה כזו בתור טוקן נפרד, ונשמור את כולם בקובץ gpt2-vocab.json, כמילון שבו לכל טוקן נתאים אינדקס. האינדקס הוא בעצם הערך המספרי של הטוקן שאותו נעביר כקלט למודל.
פענוח הפלט של המודל הוא פשוט ביותר. את הערך המספרי שנקבל נמיר לטוקן לפי gpt2-vocab.json, וכל תו בסיס נתרגם לבית המתאים לפי המילון שיצרנו מקודם.
מבנה המודל
המודל GPT-2 קיים בארבעה גדלים: small, medium, large, XL, עם 124M, 355M, 774M, 1.5B פרמטרים בהתאמה.
כזכור, GPT-2 הוא מודל מסוג transformer. ה-transformer המקורי נוצר עבור תרגום, ויש לו encoder block ו-decoder block. שני הבלוקים דומים מאוד, אך ה-decoder block משתמש ב-masked self-attention אשר "מסתיר" את המילים העתידיות בטקסט בעת האימון. GPT-2 מתבסס על ה-decoder block של ה-transformer המקורי.
נגדיר את הגדלים הבאים:
vocab_size - גודל אוצר המילים, ששווה ל-50,257.
n_embd - אורך וקטור ה-embedding של כל טוקן, מספר ה-features. משפיע גם על מימדי ה-hidden states. שווה ל-768 בגרסה הקטנה של המודל.
n_head - מספר הראשים שיש ל-multi-head attention. שווה ל-12 בגרסה הקטנה של המודל.
n_layer - מספר ה-transformer blocks. שווה ל-12 בגרסה הקטנה של המודל.
batch_size - גודל ה-batch. נקבע במהלך ההרצה.
seq_len - אורך הרצף, מספר הטוקנים בקלט. נקבע במהלך ההרצה.
n_ctx - גודל חלון הקונטקסט, אורך הרצף המקסימלי. שווה ל-1,024.

Embedding Layer
גודל הקלט של השכבה הוא (batch_size, seq_len, vocab_size), גודל הפלט הוא (batch_size, seq_len, n_embd).
כל טוקן בקלט מיוצג כ-one-hot vector. למשל, טוקן בעל ערך 5 מוצג כוקטור שבו התא באינדקס 5 שווה 1, ושאר התאים שווים 0. נוכל אפילו ליצור מטריצה של כל ה-one-hot vectors מהקלט, בה כל שורה היא טוקן אחר.
Word embedding - במקום שכל מילה תיוצג על ידי one-hot vector, אנו מעוניינים בווקטור שמייצג את משמעות המילה, בתוך מרחב לינארי שמייצג את המשמעויות של מילים. במרחב כזה, מילים בעלות משמעות דומה יהיו קרובות זו לזו. בנוסף, נוכל למשל לקבל ציר שייצג מגדר, כשבכיוון אחד שלו יהיו מילים שמזוהות עם גברים, ובכיוון השני מילים שמזוהות עם נשים. מרחב לינארי כזה יוכל אף לייצג קשרים כמו king−man+woman≈queen.
נרכיב embedding matrix שבה כל שורה i היא וקטור ה-embedding של הטוקן שערכו i. כך, נוכל לכפול את מטריצת הקלט ב-embedding matrix, ולקבל מטריצה שבה כל שורה היא ה-embedding vector של הטוקן המתאים מהקלט.
(הערה: במימוש של GPT-2 נתנו למודל ישירות את ערכי הטוקנים, והשתמשו בפונקציה של הספרייה לשליפת השורות המתאימות מה-embedding matrix. אופן הפעולה האמיתי תלוי בספרייה, אך העיקרון זהה.)

כדי שהמודל יוכל להתייחס למיקום של כל טוקן בטקסט, יש לנו מטריצה של positional encodings לקידוד מיקומי הטוקנים. כזכור, למודל יש חלון קונטקסט בגודל 1,024 טוקנים, כך שיש לנו 1,024 מיקומים אפשריים. למטריצה הזו יש 1,024 שורות, וכל שורה מייצגת מיקום אפשרי אחר בטקסט.
נסכום את המטריצה שקיבלנו מהשלב הקודם עם המטריצה הזו.
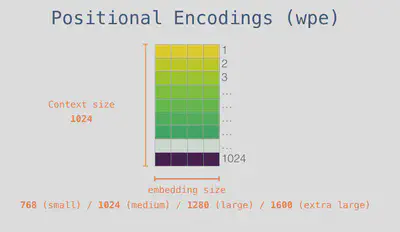
ערכי מטריצת ה-embeddings ומטריצת ה-positional encodings הם פרמטרים, אותם המודל לומד במהלך האימון.
Self-Attention Layer
גודל הקלט של השכבה הוא (batch_size, seq_len, n_embd), גודל הפלט זהה.
בעזרת self-attention, המודל יכול להתייחס להקשרים שונים במשפט. כך, המודל ילמד להבין קשרים בין מילים שונות בטקסט.
לדוגמה, ניקח את המשפט "יוסי טייל עם כלבו בשכונה וחזר לאחר שעתיים". ההקשרים השונים חשובים להבנת המשפט. למשל - מי טייל? עם מי הוא טייל? מי חזר? מתי הוא חזר? וכדומה.
עבור כל מילה בטקסט אנו שואלים שאילתה כזו, שמיוצגת כווקטור query. לכל מילה יש לנו גם וקטור מפתח (key) וגם וקטור ערך (value). נכפול את וקטור השאילתה בווקטור המפתח של כל מילה, וכך נדע כמה כל מילה בטקסט רלוונטית לשאילתה. המכפלה משמשת ציון רלוונטיות. נחבר את וקטורי הערך של כל מילה באופן משוקלל לפי ציוני הרלוונטיות וכך נקבל וקטור חדש לייצוג המילה לגביה שאלנו.
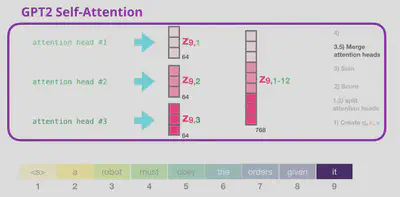
מכיוון שאנו משתמשים ב-multi-head attention, התהליך הזה קורה מספר פעמים במקביל לכל מילה, כל פעם עם וקטורי שאילתה, מפתח וערך אחרים. את הוקטורים שנקבל מכל head אנחנו משרשרים ביחד.
לאחר שהבנו את הרעיון הבסיסי של השכבה, ננסה להבין את אופן פעולתה ברמה יותר טכנית ועמוקה.
שכבת Conv1D:
בשכבת Conv1D בגודל (nx, nf), מכפילים את הקלט במטריצת weight בגודל (nx, nf) וסוכמים עם וקטור bias באורך nf. ערכי המטריצה והווקטור הינם פרמטרים. לכל הופעה של Conv1D יש weight ו-bias משלה.
את הקלט של השכבה מעבירים בשכבת Conv1D בגודל (seq_len, n_embd*3).
המטריצה שהתקבלה גדולה פי שלושה מהקלט, כך שנפצל אותה למטריצות query, key ו-value.
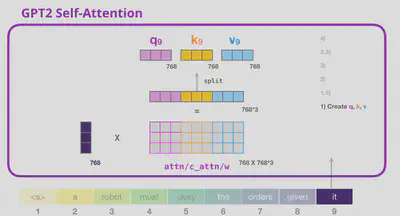
את שלוש המטריצות הללו נפצל בהתאם למספר ה-attention heads. נקבל מטריצות בגודל (batch_size, n_head, seq_len, n_embd/n_head).
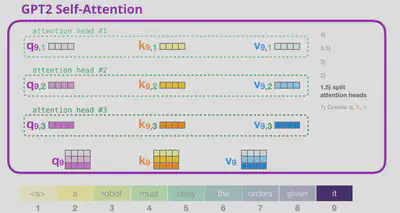
עבור כל attention head מתבצע התהליך הבא:
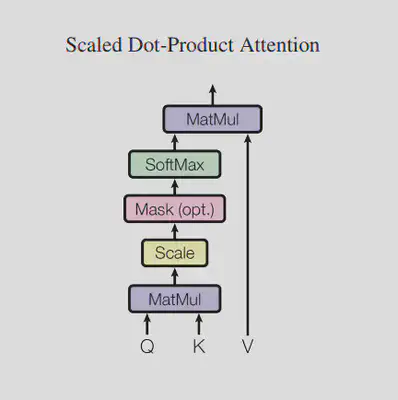
לפי הנוסחה הבאה:
$$ MaskedAttention(Q,K,V)=softmax(mask(\frac{QK^T}{\sqrt{d_k}}))V $$כאשר $d_k$ = אורך וקטור המפתח, זאת אומרת n_embd/n_head.
החלוקה ב-$\sqrt{d_k}$ משמשת להקטנת קנה המידה.
לפני ה-softmax, משתמשים ב-mask על מנת להסתיר את הטוקנים העתידיים. זאת אומרת, עבור כל טוקן, אנו לא רוצים שהטוקנים שבאים אחריו יוכלו לענות על השאילתות שלו. לכן, את ציוני הרלוונטיות (לפני softmax) של הטוקנים העתידיים נחליף במספר מאוד קטן (אצל OpenAI זה מינוס 1e10, אצל Hugging Face זה מינוס 1e4).


ה-softmax נותן לנו מטריצה עם ציוני הרלוונטיות, כשכל שורה מתאימה לטוקן עליו שאלנו שאילתה, וכל עמודה לטוקן שעונה על השאליתה. לבסוף מכפילים במטריצת הערכים, כך שנקבל מטריצה שבה כל שורה מתאימה לטוקן עליו שאלנו שאילתה, כווקטור משוקלל של ערכי התשובות לפי ציוני הרלוונטיות. המטריצה הזו בגודל (batch_size, n_head, seq_len, n_embd/n_head).
לאחר מכן אנו משרשרים ביחד את תוצאות ה-attention heads (למעשה פעולה הפוכה מהפיצול שעשינו מקודם) בשביל לקבל מטריצה בגודל (batch_size, seq_len, n_embd).
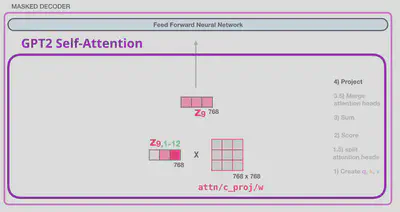
לבסוף, לפני שמעבירים ל-feed forward layer, מעבירים בשכבת Conv1D בגודל (n_embd, n_embd). המימדים לא משתנים.
Feed Forward Layer
גודל הקלט של השכבה הוא (batch_size, seq_len, n_embd), גודל הפלט זהה.
זוהי שכבה מאוד פשוטה.
תחילה מעבירים את הקלט בשכבת Conv1D בגודל (n_embd, n_embd*4).
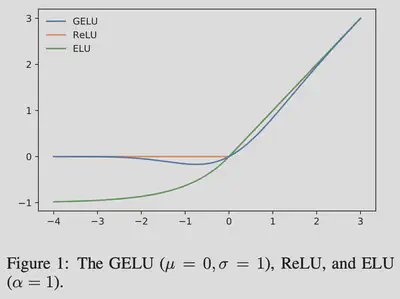
לאחר מכן מפעילים פונקציית אקטיבציה GELU (ראשי תיבות של Gaussian Error Linear Unit).
הפונקציה שווה בקירוב:
$$ GELU\approx\frac{1}{2}x(1+tanh[\sqrt{\frac{2}{\pi}}(x+0.044715x^3)]) $$מימושים ישנים של המודל משתמשים בנוסחה המקורבת הזו (נכתבו לפני שחישוב מהיר של הפונקציה היה קיים בספריות PyTorch ו-TensorFlow).
לבסוף, מעבירים בשכבת Conv1D בגודל (n_embd*4, n_embd) כדי להחזיר לגודל המקורי.
Transformer Block
גודל הקלט של הבלוק הוא (batch_size, seq_len, n_embd), גודל הפלט זהה.
ה-transformer block מורכב מ-self-attention layer, מ-feed forward layer ומשכבות layer normalization.
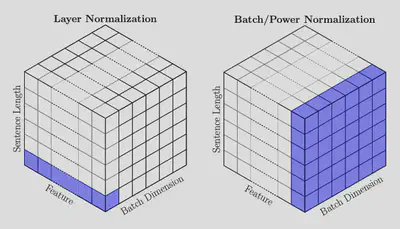
שכבת LayerNorm:
עבור טוקן במקום ה-i, כאשר m=n_embd.
$\mu_i=\frac{1}{m}\sum_{j=1}^{m}x_{i,j}$ (ממוצע)
$\sigma_i^2=\frac{1}{m}\sum_{j=1}^{m}(x_{i,j}-\mu_i)^2$ (שונות, variance)
$\hat{x}_i=\frac{x_i-\mu_i}{\sqrt{\sigma_i^2+\epsilon}}$
$LN_{\gamma,\beta}(x_i)=\gamma\hat{x}_i+\beta$
כאשר $\epsilon=1e-5$.γ, β הם וקטורים באורך n_embd. שניהם פרמטרים. לכל הופעה של LayerNorm יש γ, β משלה.
להלן פסאודו קוד של הבלוק:
TransformerBlock(x):
a = SelfAttention(LayerNorm1(x))
x = x + a
f = FeedForward(LayerNorm2(x))
x = x + f
return x
שכבת הפלט
גודל הקלט של השכבה הוא (batch_size, seq_len, n_embd), גודל הפלט הוא (batch_size, seq_len, vocab_size).
לאחר כל ה-transformer blocks, מעבירים דרך layer normalization אחרון.
מכפילים בשחלוף (transpose) של ה-embedding matrix, ומקבלים מטריצה בגודל (batch_size, seq_len, vocab_size).
המטריצה שקיבלנו הינה מטריצה של לוג׳יטים (logits). לוג׳יט מייצג הסתברות בין מינוס אינסוף לאינסוף (זאת אומרת, לפני הפעלת softmax). כל עמודה מייצגת את ההסתברות של טוקן אחר מאוצר המילים להיות הטוקן הבא, וכל שורה מייצגת את הטוקן האחרון הנתון. עבור טוקן במקום ה-i בקלט המודל, השורה במקום ה-i מכילה את הלוג׳יטים לחיזוי הטוקן שבא אחריו. עבור טוקן במקום ה-j באוצר המילים, העמודה במקום ה-j מכילה את הלוג׳יטים שלו להיות הטוקן הבא בטקסט.
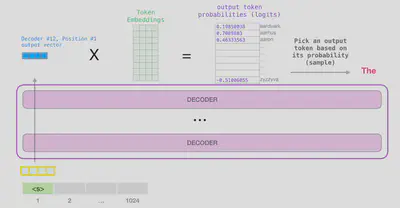
פונקציית העלות
מבחינת המינוח:
פונקציית הפסד - loss function - לפי דוגמה אחת.
פונקציית עלות - cost function - ממוצע ההפסדים.
כזכור, פלט המודל הוא בלוג׳יטים. לכן, נרצה להפעיל פונקציית softmax כדי לקבל הסתברויות בין 0 ל-1, שנסכמות ל-1. $$ Softmax(x_{i,j})=\frac{exp(x_{i,j})}{\sum_{k=1}^{K}exp(x_{i,k})} $$ המודל משתמש ב-categorical cross entropy loss: $$ CELoss(\hat{y}_i,y_i)=-\sum_{j=1}^{K}y_{i,j}\times log(\hat{y}_{i,j}) $$ K למעשה שווה ל-vocab_size. ל-$y_{i,j}$ יש ערך של 0 או 1, כך שאנו סוכמים את מינוס לוגריתם ההסתברויות של הטוקנים הבאים הנכונים. מכיוון שיש לנו רק טוקן אחד נכון, ההפסד למעשה שווה למינוס לוגריתם ההסתברות של הטוקן הנכון.
בעזרת cross entropy, אנו יכולים להשוות בין ההתפלגות של ה-language model, לבין ההתפלגות "האמיתית" של השפה. מכיוון שאנו לא יכולים באמת לדעת את ההתפלגות האמיתית של השפה, אנו משווים להתפלגות השפתית במאגר הטקסט.
כאשר נשתמש ב-torch.nn.CrossEntropyLoss או ב-tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) אנו יכולים להעביר ישירות את הלוג׳יטים, וה-softmax יחושב ביחד עם העלות.
לבדיקה על סט הוולידציה או על סט הבדיקה, נעדיף להשתמש במדד אחר:
Perplexity - מדד ליכולת של המודל לחזות את הטוקן הבא בטקסט. ככל שנמוך יותר, היכולת טובה יותר. מודד את רמת אי-הוודאות של המודל בבחירת הטוקן הנכון הבא בקטע טקסט. מדד שרלוונטי בעיקר בשלב האבלואציה על סט הוולידציה או על סט הבדיקה.
$$ PP=e^{CECost} $$(הערה: בסיס החזקה צריך להתאים לבסיס הלוגריתם של ה-cross entropy. למרות שמקובל להשתמש בבסיס 2, ספריות כמו TensorFlow ו-Pytorch נוהגות להשתמש בלוגריתם טבעי.)
יש לשים לב שמעריך החזקה הינו העלות, cost, ששווה לממוצע ההפסדים.
חיפוש ודגימה בשלב הפענוח
כזכור, מפלט המודל נקבל לוג׳יטים המייצגים הסתברות בין מינוס אינסוף לאינסוף של כל טוקן מאוצר המילים להיות הטוקן הבא. אנו יכולים בכל צעד לבחור את הטוקן עם הלוג׳יט הגדול ביותר. לשיטה הזו קוראים greedy search, אולם היא נוטה לפספס מילים עם הסתברות גבוהה ש"מתחבאות" מאחורי מילים עם הסתברות נמוכה. כך, הרצף הסופי עלול להיות בעל הסתברות שקולה נמוכה יותר.
Beam search - נסתכל על ה-n טוקנים עם ההסתברות הגבוהה ביותר. בצעד הבא, נסתכל על ה-n טוקנים הבאים עבור כל הטוקנים מהצעד הקודם, וכך הלאה. כפי שניתן לראות באיור, בכל צעד נפצל כל "קרן" ל-n קרניים. בסופו של דבר, נבחר את הרצף בעל ההסתברות השקולה הגבוהה ביותר.
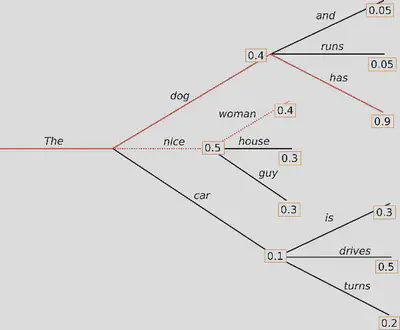
ביצירת טקסט מתמשך, כאשר אורך הטקסט הסופי אינו צפוי (לעומת תרגום או סיכום), מקובל דווקא להשתמש בדגימה.
בתחילת כל צעד, נסנן את הלוג׳יטים לפי אחת השיטות הללו (או עם שתיהן יחדיו):
Top-k sampling - נבחר את ה-k לוג׳יטים הכי גדולים.
Top-p (nucleus) sampling - נבחר את הלוג׳יטים הגדולים ביותר שסכום ההסתברויות שלהם (לאחר softmax) עובר את p.
לאחר הסינון, נפעיל פונקציית softmax כדי לקבל הסתברויות בין 0 ל-1, שנסכמות ל-1.
לבסוף, נבחר טוקן באקראיות, כשההסתברות לבחירת כל טוקן שווה לערך ה-softmax שלו.
לעיתים, לפני הפעלת ה-softmax נחלק את הלוג׳יטים בערך טמפרטורה. הורדת הטמפרטורה תחדד את ההתפלגות ולוג׳יטים גדולים יקבלו ערך softmax גבוה יותר לעומת לוג׳יטים קטנים. טמפרטורה 1.0 כמובן לא תשפיע.
מקורות ולקריאה נוספת
- The Illustrated GPT-2 (Visualizing Transformer Language Models) – Jay Alammar מכאן לקוחים האיורים הצבעוניים של מבנה המודל. השימוש תחת רישיון CC BY-NC-SA 4.0.
- The Annotated GPT-2 | Committed towards better future
- gpt-2/model.py at master · openai/gpt-2 · GitHub
- gpt-2/encoder.py at master · openai/gpt-2 · GitHub
- Summary of the tokenizers - Byte-Pair Encoding (BPE)
- Byte-Pair Encoding: Subword-based tokenization algorithm
- Evaluation Metrics for Language Modeling
- How to generate text: using different decoding methods for language generation with Transformers
0 תגובות
תודה!
התגובה נשלחה ותפורסם ברגע שתאושר.
אוקיי
אופס!
שליחת התגובה נכשלה. אנא נסו שוב.
אוקיי